
An image dataset for surveillance of personal protective equipment adherence in healthcare

Bounding Box Analysis
The R2PPE dataset is characterized by a dense concentration of bounding boxes within each image. To show the uniqueness of this density, we compared it with the density of three other datasets: Pattern Analysis, Statistical Modelling and Computational Learning Visual Object Classes (PASCAL VOC)16, COCO15, and CPPE-5. PASCAL VOC and COCO were selected because these datasets are widely recognized benchmarks in the object detection field. CPPE-5 was selected because it is the most current medical PPE dataset and is most closely aligned with the context of our work. For the R2PPE dataset, the average number of bounding boxes per image is 12.4, which is higher than 2.5 in PASCAL VOC and 7.3 in COCO. R2PPE also features denser annotation compared to CPPE-5, which averages 4.5 bounding boxes per image. The high density in R2PPE results from images with a higher number of adherence and nonadherence classes, along with heavily overlapping bounding boxes.
Our dataset accounts for the aspect ratio of bounding boxes, calculated by dividing the width of the box by its height. These variations in aspect ratios present challenges for object detection models, especially for those that rely on predefined anchor box shapes and sizes. Detection models may perform less effectively on datasets with a wide range of aspect ratios, while boxes with extreme aspect ratios introduce other detection challenges17. For example, boxes with extreme aspect ratios can lead to an imbalanced distribution of feature map resolutions, hindering the model’s ability to learn effective representations required for accurate object detection. A histogram of the aspect ratios derived from the bounding boxes in our dataset shows a predominant concentration around 1, with a tail extending towards higher ratios (Fig. 5a). We also analyzed the ratio of each bounding box’s area to the overall image area (Fig. 5b). Because the frame images are captured by a fixed camera at a high resolution of 1080 × 1920 pixels, the bounding box areas are relatively small compared to the overall image size. Small bounding boxes increase localization errors and reduce the number of features available for classification. For researchers in the object detection field, these small bounding boxes may pose a challenge that requires accurate identification of details within the images.
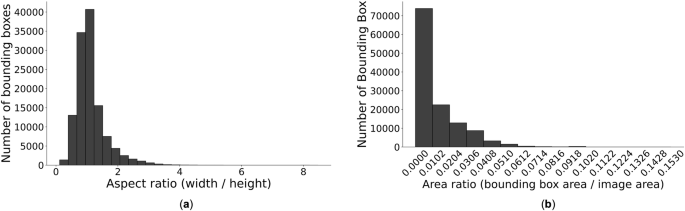
Bounding box aspect and area ratio distributions in the dataset images. (a) Bounding box aspect ratio distribution. (b) Bounding box area ratio distribution.
Image Density Metrics
We introduce two metrics to highlight the unique characteristics of the R2PPE dataset and to benchmark it against other public datasets. These metrics provide an insight into the challenges in detecting target bounding boxes in images with densely populated annotations. We define local density Dl as a measure of the extent to which each bounding box overlaps with others within the same image, reflecting the concentration of objects in specific image areas. We also introduce global density Dg, a measure of the crowdedness of bounding boxes in the entire image. This metric provides a holistic measure of object density across the image space. By measuring density within specific image areas (i.e., locally) and across the entire image space (i.e., globally), we can gain insight into the challenges of achieving accurate object detection in high-density scenarios.
For an image X, the function B(X) yields the number of bounding boxes within it, each designated as bi, with i ranging from 1 to B. The Intersection over Union (IoU) for any pair of bounding boxes is computed as the ratio of the area of their intersection to the area of their union:
$$IoU(b_i,b_j)=\fracI(b_i,b_j)A(b_i)+A(b_j)-I(b_i,b_j),$$
(1)
where the function A(⋅) computes the area of a bounding box, and the function I( ⋅, ⋅ ) represents the intersection area between two bounding boxes. We then determine the maximum IoU for a bounding box with any other bounding boxes within the same image. The local density of image X, represented as Dl, is defined as the average of these maximum IoUs for all bounding boxes present in the image:
$$D_l(X)=\frac1N\mathop\sum \limits_i=1^N\mathop\max \limits_j\in \1,2,\,…,\,N\\backslash \i\IoU(b_i,b_j).$$
(2)
The global density, Dg, is defined as the number of bounding boxes within image X:
By integrating the measures of local (i.e., specific areas within an image) and global (i.e., the entire image space) density, we can gain insights into both the number of bounding boxes present in an image and their distribution across the entire image view.
To evaluate the distinctions between our dataset and other prevalent public datasets, we determined the local and global densities for images in PASCAL VOC, COCO, CPPE-5 and the R2PPE dataset (Fig. 6). Local density estimations for PASCAL VOC, COCO, and CPPE-5 cluster around zero, indicating that bounding boxes do not overlap in most images (Fig. 6a). In contrast, images in R2PPE mostly have a local density near 0.2. This result implies a higher prevalence of overlapping bounding boxes in the R2PPE dataset. A similar trend is observed for global density (Fig. 6b). PPE datasets, CPPE-5 and R2PPE, exhibit a greater number of bounding boxes per image in comparison to the general-purpose datasets (PASCAL VOC and COCO) because a person wears multiple PPE categories. Our analysis suggests that the R2PPE dataset with its realistic features is more adequate for training object detection algorithms in medical domains than other available datasets.

Comparison of R2PPE and three other relevant datasets using local and global density. The x-axis represents density, and the y-axis represents the proportion of data points proximate to the corresponding x-value relative to the total data count. (a) Local density Dl. (b) Global density Dg.
To encourage targeted algorithm optimization and benchmark the performance of algorithms under different conditions, we divided our dataset into low-complexity (R2PPE-L) and high-complexity (R2PPE-H) segments using local density as a criterion. In real-world scenarios, healthcare workers often either congregate around the bed or move across the room. This difference in provider location and movement creates a complex scene and makes it challenging to draw a clear boundary to separate images with different levels of complexity. To address this challenge, the local density of images can serve as a criterion. We sorted all images in the R2PPE dataset by their local density and categorized them into a simple subset with low density (R2PPE-L) and a difficult subset with high density (R2PPE-H). We selected a threshold of 0.28 based on the local density curve (Fig. 6a). At this threshold, the curve transitions from a steep decline to a more gradual slope. This change in the trend indicates a shift in the density distribution, making 0.28 a natural threshold for dividing the dataset into subsets with distinct density characteristics. Images with local densities surpassing the threshold are classified under R2PPE-H, while others are allocated to R2PPE-L.
Model Detection Results
The high-density characteristic in the R2PPE dataset poses unique challenges for existing object detection models. To evaluate the adaptability of object detection models to our dataset, we applied several commonly used models. These object detection models are categorized into one-stage18,19 and two-stage detectors20,21,22. For our experiments, we selected You Only Look Once (YOLO)19 and Faster Region-based Convolutional Neural Network (Faster R-CNN)20 as representative baseline models from the one- and two-stage categories, respectively, due to their widespread recognition in the object detection field. We also included the Real-Time Detection Transformer (RT-DETR)23 model to represent frameworks based on the emerging use of the transformer architecture24. We randomly partitioned the dataset into training and test sets with a ratio of 80:20. Pre-trained on the COCO dataset, the three representative models were finetuned on the R2PPE training set without any modifications to their architectures. We used PyTorch25 for all baseline experiments, with the detectron2 library ( for Faster R-CNN and the Ultralytics library ( for YOLO and RT-DETR. The specific configurations were faster_rcnn_R_101_FPN_3x.yaml for Faster R-CNN, yolov5l.pt for YOLO, and rtdetr-x.pt for RT-DETR. Each model was trained for 80 epochs. We evaluated the performance of each model by calculating the Average Precision (AP) score for each class, specifically employing the AP[0.5:0.05:0.95] metric, a standard evaluation metric derived from the COCO dataset benchmarks. This metric computes the AP by averaging over a range of IoU thresholds, starting from 0.50 to 0.95 in increments of 0.05 (Table 4).
In the evaluation of the three object detection models on our dataset, several insights emerged. First, the consistent performance across the three models indicates the integrity of the dataset, showing that a particular detection methodology was not favored. Moreover, across all classes in our dataset, the models achieved AP scores that closely align with their performances on the COCO dataset, with Faster R-CNN at 42%, YOLOv5 at 49% and RT-DETR at 54.8%, despite the COCO dataset containing five times more classes than R2PPE. This similarity in performance and the difference in the number of classes highlight the distinctive challenges our dataset poses. Among the three models, YOLOv5 outperformed its counterparts. This advantage is due to its real-time detection capabilities and direct bounding box predictions, which are particularly effective in handling small and densely packed objects. The feature pyramid network (FPN) in YOLOv5 enhances its ability to detect objects at multiple scales, making it well-suited for high-density, small-object scenarios present in the R2PPE dataset. These results suggest that future work could further explore one-stage detectors for PPE detection in the R2PPE dataset. A common challenge encountered by all models was the detection of mask classes, likely due to smaller bounding box sizes, occlusions and the nuanced differences between “mask absent” and “mask incomplete” classes. This challenge is also an area that deserves special attention in future research.
link





